When conceptualizing a service or product based on data, I first transform visions into a tangible visualization or prototype that anyone in a multi-disciplinary team can feel and understand. Additionally, I generally create Design Fictions that explore possible appropriations of the envisioned data product along its life. Taken together, prototypes and fictions present tangible concepts that help anticipate opportunities and challenges for engineering and user experience before a project gets even founded. These concepts give a clearer direction on what you are planning to build. They are a powerful material to explain the new data product to others and they act as a North Star for a whole team has a shared vision on what they might to want build.
Taken together, prototypes and fictions present tangible concepts that help anticipate opportunities and challenges for engineering and user experience before a project gets even founded.
This is the approach I aimed to communicate last week in a 5-days workshop at HEAD design school in Geneva to an heterogeneous group of students coming from graphic design, engineering, business or art backgrounds.

Part 1: Sketching with Data
 The first part of the workshop was dedicating to become familiar with the theories and practices related to data science, data visualization, and information design. Along with Julian Jamarillo from Bestiario, we introduced different ways of extracting insights from data and convey a message effectively from the simple result of a collaborative filtering algorithm to the proper use of a map or a chart. The main objective for the students was to acquire a hands-on experience visualizing data and transform them into small stories.
The first part of the workshop was dedicating to become familiar with the theories and practices related to data science, data visualization, and information design. Along with Julian Jamarillo from Bestiario, we introduced different ways of extracting insights from data and convey a message effectively from the simple result of a collaborative filtering algorithm to the proper use of a map or a chart. The main objective for the students was to acquire a hands-on experience visualizing data and transform them into small stories.
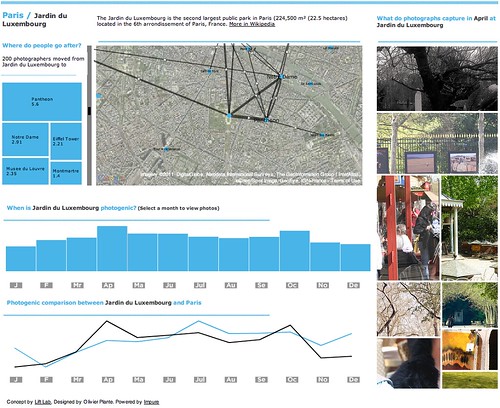
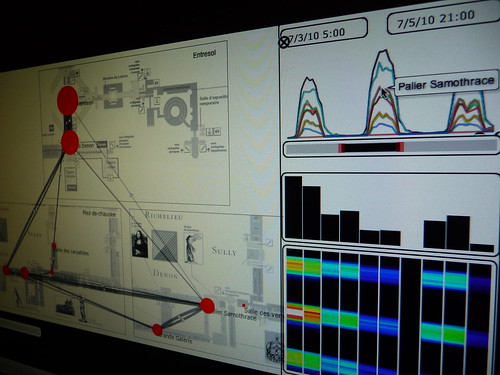
 For instance, through the manipulation of a real dataset participants apprehended its multiple dimensions: spatial, temporal, quantitative, qualitative, their objectivity, subjectivity, granularity, etc. It only took a full day of sketching with data with Quadrigram, for participants to start write and tell small stories about crime in San Francisco or mobility in Barcelona. Embedded as a data-driven web page, we motivated students to provide a critical eye on the current hype about big data: What are the limitations? Do they tell a story but not THE story? Consequently, we discussed the notions of trust, quality and integrity of the sources, the ownership of personal data, and the subjectivity in many design decisions to convey a message.
For instance, through the manipulation of a real dataset participants apprehended its multiple dimensions: spatial, temporal, quantitative, qualitative, their objectivity, subjectivity, granularity, etc. It only took a full day of sketching with data with Quadrigram, for participants to start write and tell small stories about crime in San Francisco or mobility in Barcelona. Embedded as a data-driven web page, we motivated students to provide a critical eye on the current hype about big data: What are the limitations? Do they tell a story but not THE story? Consequently, we discussed the notions of trust, quality and integrity of the sources, the ownership of personal data, and the subjectivity in many design decisions to convey a message.
Through the manipulation of a real dataset participants apprehended its multiple dimensions: spatial, temporal, quantitative, qualitative, their objectivity, subjectivity, granularity, etc.
Part 2: Creating implications
 In the second part of the workshop we projected into the future the datasets and their stories. We started to imagine a future service, product, solution that link data to fashion, entertainment, the environment, social relations, etc. Using an approach called Design Fiction, we encouraged participants to build elements of a possible data product without being too precious or detailed about them. The aim was to spark conversations about the near future of data, check the sanity of visions and uncover hidden perspectives.
In the second part of the workshop we projected into the future the datasets and their stories. We started to imagine a future service, product, solution that link data to fashion, entertainment, the environment, social relations, etc. Using an approach called Design Fiction, we encouraged participants to build elements of a possible data product without being too precious or detailed about them. The aim was to spark conversations about the near future of data, check the sanity of visions and uncover hidden perspectives.
A Design Fiction approach to bring a technology to the world starts by anticipating how people could co-evolve with it. Instead of designing for Time 0 (T) when people start using a data product or service, I believe it is important to consider the evolution of the user experience with its frictions, rituals, and behaviors at T+ 1 minute, T+ 1 hour, T+1 day, T+1 week, T+1 month, etc. until the actual end of life of the product (e.g. what happens to my data when I retire my Fitbit into my box of old devises).

Hence, in our workshop, similar to Amazon’s Working Backward process of service design, we asked students to write first a press release that describes in a simple way what a potential data product does and why it exists. The format of the press release is practical because it is not escapist. It forces to use precise words to describe a thing and its ecosystem (e.g. who built it, who uses it, what does it complement, what is it built with?).
Writing a fictional press release forces to use precise words to describe a thing and its ecosystem. Quite naturally it leads to listing Frequently Asked Questions with the banal yet key elements that define what the data product is good for.
With the press release in hands, the next exercise consisted in “cross-pitching” their concepts for 2 minutes to each other. Quite naturally, from the questions that came up during the exchange some participants started to list the Frequently Asked Questions (FAQ). The FAQ includes the banal yet key elements that define what the data product is good for. That exercise forced participants to consider the different situations and frictions users could have along the life of a product.
As the concepts clarified, we sketched storyboards of use cases and mocked up interfaces that described in more details the user experience with the product. Finally, each embryonic concepts of data product became alive with the production of a piece of design fiction.
 In Design Fiction, we use cheap and quick content production material (e.g. video, data visualization, print, interface mockups, …) to make things (e.g. diegetic prototypes) as if they were real. For instance, one student project took the form of the user manual of a smart jacket that shows how a customer should use it, what personal data are exploited, how the information is revealed.
In Design Fiction, we use cheap and quick content production material (e.g. video, data visualization, print, interface mockups, …) to make things (e.g. diegetic prototypes) as if they were real. For instance, one student project took the form of the user manual of a smart jacket that shows how a customer should use it, what personal data are exploited, how the information is revealed.
This type of exploration serves to design-develop prototypes and shape in order to discard them, make them better, or reconsider what we may take for granted today. It served at considering the data product and its implications. The Design Fictions act as a totem for discussion and evaluation of changes that could bend visions and trajectories. They are some sort of “boundary objects” that allow heterogeneous groups of participants to understand with a common language the exploitation of data and their instantiation into a product or service.
Some of the created and discussed implications include the Fashion Skin jacket that explore through a user manual the affordance of smart clothes and how people might interact with contextual information. The press release says:
The Fashion’Skin, with its unique sensing and adaptive fabric, is a revolution in the fashion and the smart clothing landscapes. It is always accorded to the people’s feelings, the weather, or the situation, without compromise. The fabric can change its color, its texture and its form.
Others looked at the data intake rituals of the near future and the hegemony of mean-well technologies with Noledge a data patch that transfer knowledge on languages directly into your brain. Here is its unboxing video.
Almost all groups looked at the virtues and pitfall of feedback loops. For instance Real Tennis Evo for the Wii™i that models data generated with Wilson-Sony rackets into simulations of one-self. The game cover advertises that “you can improve your skills by playing against your real self at home”.

Data visualizations help extract insights, and prototypes force to consider the practical uses of those insights. Design fictions put prototypes and visualization in the context of the everyday life.
Take aways
Data visualizations, prototypes and design fiction are ‘tools’ to experiment with data and project concepts into potential futures. They help uncover the unknown unknowns, the hidden opportunities and unexpected challenges.
Data visualizations help extract insights, and prototypes force to consider the practical uses of those insights. Design fictions put prototypes and visualization in the context of the everyday life. They help form a concept and evaluate its implications. The approach works well for abstract concepts because it forces you to work backward and explore the artifacts or the byproducts linked to your vision (e.g. a user manual, an advertisement, a press release, a negative customer review …). Eventually the approach encourages considering the ecosystem affected by the presence of a data product: What do people do with it over time? Where are the technical, social, legal boundaries?
Thanks to Daniel Sciboz and Nicolas Nova for the invitation, Julian Jamarillo and Bestiario to share their practice and Quadrigram and the students of HEAD and HEG for their creativity, energy and capacity to leave their comfort zone in design, engineering, business and art.