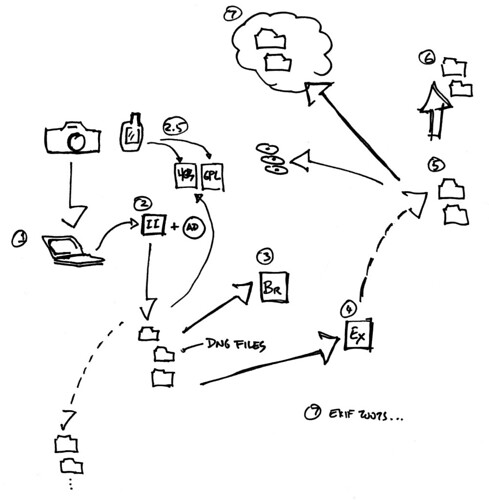
Cross off one goal on the list of things for 2009. I’ve managed to create a rugged imaging work flow which has all the characteristics of an over-wrought, over-the-top Balkan bureaucracy. Nevertheless, it works for me for the time being, although I’m fairly certain there’s a quagmire of snafus and lost data lurking just around the corner.
I pretty much got annoyed with the pre-packaged image management tools — or dubiously named DAM (digital asset management) tools and protocols. Aperture and Lightroom feel like they’re trying to do too much and have a number of nuisance restrictions on where the actual media goes. Plus, they have these mysterious library files that grow and grow. I mean — I know they’re containers for media and the media’s in there, but that just feels like a recipe for (a) disaster; (b) inability to do incremental backups on just what’s changed so that my backup routine always ends up copying ginormous 4GB+ “libraries” even if I’ve only added one 27kB file. Ridiculous. I could never get used to their all-in-one feel. So, I moved on. I’m not prepared to say this is the be-all-to-end-all routine, but so far it’s working okay. It’ll fail at some point, like a things digital must.
Here’s the drill.
(1) Image ingestion to my Mac from my camera.
(2) I use ImageIngestor. By far, thus far, the better of image ingestion tools. I like that it has macros that allow me to specify how to rename images so I can name them with a human date and time, which will also sort them if I chose to do so in a directory listing. I like that it allows me to cohere the photos with GPX track data that comes from GPS data, should I happen to have that. All around great image ingestion tool.
I tell Image Ingestor to do automatic DNG conversion using the free Adobe DNG Converter. I add a large JPEG preview to the DNG. I instruct Image Ingestor to leave behind backups of the pre-conversion RAW (NEF) files in a shadow directory that I throw out when I notice that they’re there, just in case I frack something up.
(2.5) I sometimes have a good GPS with great sensitivity packed in my bag, shoved in a big pocket or lying in my car somewhere. It’s a Garmin GPSMap 60CSX, which works well without being fussed over. In my opinion, it’s a better solution than the bulky, awkward, cord-y GPS devices that mount on a camera’s flash hot shoe. I’ve tried those. They’re bunk. You can’t change out the batteries, they have middling cold-star fix capabilities, the cable gets tangled up with anything it pleases, they’re plastic, bulk up the camera, make me look weirder than I already do shooting a big DSLR with a Nikon 14mm fisheye. With the Garmin, I have a GPS that’ll take normal, human AA batteries and lets me fiddle with its settings. Someday soon pro DSLRs will have a really good GPS built in that might just work as well as just a normal GPS. For the time being, a normal GPS does exactly what I need it to — give me rough location data that I can assign to images. (Why I do this is as neurotic an obsession as actually putting together an obsessive imaging workflow.)
I use the free HoudahGPS to download GPS tracks over USB from my GPS. (This wasn’t always easy on a Mac. I remember the days when I had to use a serial to USB dongle and GPSBabel to hopefully extract track data.
The GPS tracks, in GPX format files, contain roughly where I was when a photo was taken. Sometimes its off. In the simplest of cases, I can match any things like time difference using Image Ingestor, which allows me to adjust any time differences due to, for example, forgetting to set the correct timezone in the camera’s clock. Otherwise, I have to resort to using GPS Photo Linker, which allows me to go image by image and have GPS Photo Linker adjust or enter location data directly. It’s a bit manual, and slow cause it tries its best to load the image files but does so as if you have all the time in the world — but takes care of inevitable foul ups.
(3) Okay. Now I have a directory hierarchy (year/human month/date) in which are DNG images. What next? Adobe Bridge CS4. Here I can do bridge-y things, like browse the images and make Camera RAW adjustments, or create derivative files, like JPEGs for upload to Flickr. (As it turns out, Picture Sync can take a DNG file and do the JPEG conversion for you before it uploads to your favorite photo service., which saves a step if you use Picture Sync.) You can do keyword tagging and other stuff here in Bridge. The interface is horrid though, so I just use it as a browser for picking images to open in Camera RAW, wherein I make adjustments to my eyeball’s liking. Then..I’m out.
(4) Cataloging. Basically, I’ve done ingestion and adjustments. I don’t linger over either of those, really. I’m not selling photos or taking them at a professional clip. I spend more time pondering how to organize the images, fueled on by a modest fear of not being able to find an image someday. (Ultimately, I think I mostly browse images nostalgically, but someday I may need something for a presentation or whatever.)
Years ago, I was using iView Media Pro quite happily and then I switched to iPhoto without thinking about it too hard. Then I noticed that iPhoto was creating zillions of preview images and generally having its way with my hard disk space, so I gave it the boot and essentially used the Finder and Finder enhancements like Pathfinder and Coverflow to browse directory hierarchies organized by date. Flickr helped too, as a catalog because I was uploading most everything to one place or another.
Well, the new drill has me back to the Microsoft incarnation of iView Media Pro, which they renamed Expression Media 2. It’s iView Media Pro, but newer and, I assume but am likely horribly wrong — better.
What’s it do? Well, it’s a cataloging program that allows for keywording, can handle hierarchical keywords (albeit not particularly well), browsing, publishing — a bunch of crap. Mostly I’m keywording images as best I can and organizing things by named sets as best I can. I’ve pretty much given up on having a controlled vocabulary or regular process. I do what I can — and move along.
What I like about Expression Media 2 is that I can disperse my media where I like. So, when I first have Expression Media 2 scan my ingestion files? I can keyword them and do whatever other “meta” stuff I want and, later, I can move the files using Expression Media 2 to an external drive or elsewhere. The keywords stick with the files, Expression Media 2 just updates where the image goes and, in the situation where an image is offline cause I don’t have the right drive hooked up or whatever — Expression Media 2 lets me know that, and will still show me a lightweight preview.
That’s pretty much what I do in the cataloging part of the workflow. Simple keywording, some categorization tags that EM2 gives you. Then, by the end of the month (there’s only been one month since I’ve done this, so who knows if that’s a rule..) I would have taken all the images in the ingestion directories and had EM2 move them to an external drive with a hierarchy of directory “bins”, each “bin” directory no larger than about 4.7GB — the size of a DVD. The directory bins themselves contain directories that are named roughly as to the content of the images therein. Something like — “Tokyo 2008.” That’s good enough. There are bound to be images that are a bit of an orphan with no ur-topic to assign them a directory. These go into a directory named by the month and year — a kind of catch all for things that have no place.
Downside of EM2 as a cataloging program are a couple of annoyances. The interface is just okay — it can get awkward entering keywords to always have to click to create a new entry rather than just doing comma separated entry really quickly. It offers you a latitude/longitude/altitude field for the IPTC data of an image — but it turns out the canonical place to put that is in the EXIF data, which it, bafflingly, does not allow you to edit. So, you can type in your latitude/longitude/altitude, but many places/sites/tools that actually use that information look for it in the EXIF data, not the IPTC data. Complete fail. I think it’s crazy that the tool locks the EXIF data. They have a reason you can hunt for in the forums but, basically — it’s bone headed.
(5) My photo drive. A 1TB drive that like won’t get close to filling up before its technology is obsolete. It’s just a hierarchy of directories that contain directories that contain images. Each top level directory grows until it contains about a DVDs worth of images, and then I’ll burn it to DVD — although that may just be a waste of time considering that that media decays over time. Probably better to do a hard drive backup, keep a backup drive somewhere else and also backup to an online data service in the “Cloud.”
(6) A mirror of the photo drive that’s a bit smaller. Just for redundancy. I backup from the original every so often.
(7) Cloud storage. I use Jungle Disk to backup my photo drive to Amazon’s S3 cloud. That was a bit of an experiment to get some experience working with this cloud stuff. How well does it work in the workflow? What does it really cost after a couple of months of usage? Stuff like that. Last months charges where $2.28. I transferred in 2.325 GB, transferred out 0.348 GB, made a couple 10’s of thousands of requests to do stuff in the process of transferring in and out of data, and stored 12.611 GB on average over the course of the month. So, I’m okay with that $2.28.
Jungle Disk takes care of the backups, with a bit of fiddling and configuring. Of course, you can basically store anything that can be moved over a TCP/IP connection on the S3 service, so it could also be a system backup, albeit quite slow. I signed up for Jungle Disk Pro, so I can gain access to my files via a web browser, which I’ve only tried once, but I like the peace of mind that suggests. Worth the — whatever..$1 a month.
(7, also) ExifTool. Sometimes I use a set of simple scripts created for viewing and editing Exif data. ExifTool is a programming library written in Perl with a lot of features. I use it to write simple scripts that can run through my photo directories (which are only roughly organized by date) and do some renaming and indexing based on date. It’s something EM2 can do, too. I just like to be able to do it without relying on that.
That’s it. My over-the-top imaging workflow. Really, it’s probably too complex but I geeked out and tooled up.